Author here. I wish I had made it clearer that the intent of the post was "this is an interesting and surprising thing you can achieve in C" and not "this is a good idea for a real software project" or "this is a reason to use C instead of C++/Rust/Go".
Macros of this sort are indeed used to define stacks, queues, deques, and other generic data structures in the NetBSD (and presumably other BSDs) source code. So the pattern is used in real software projects.
> Author here. I wish I had made it clearer that the intent of the post was "this is an interesting and surprising thing you can achieve in C" and not "this is a good idea for a real software project" or "this is a reason to use C instead of C++/Rust/Go".
thanks, because from my experience edgy first year comp.sci. students will see that article and be like "see ! we don't need anything more than C!"
A better pattern instead of declaring via a macro that expands to a large number of functions is to define the implementation in a file, require the user to #define STACK_T and then #include the file. At the bottom of the file, #undef STACK_T. As files can be included multiple times, you can do this for each generic structure you like. A sort of poor-man’s templates, that you can reasonably step through in a debugger.
Yes! The include style of templates in C is way better than the old way of huge macros to instantiate code. The template code can look mostly like idiomatic C, it interacts way better with a debugger, it gives better compiler errors... everything about it is better and it's finally starting to become more popular.
Not only does it use the #include style of templates, but it actually makes the templates composable. It takes this idea pretty far, for example having a lifecycle template that lets you define operations on your type like move, copy, destroy, etc. This way the containers can fully manage the lifecycles of your types even if they're not bitwise movable.
There's also this other more popular C template library, one that tries to more directly port C++ templates to C but with a lot less features:
Header only implementations of data structures are definitely the only way to accomplish type-safe generics in C, which is a great reason to avoid C! It's part of the reason why all C code bases eventually become a kind of unique, macro filled language of their own once they grow complex enough. It's not enough to know C to start working on this code, you have to know all the ins and outs of the weird macro expansions that form the boilerplate patterns and are unique to this codebase only.
Apart from being a pain in the ass to write (don't forget your escape slashes (\) for line endings!), using these macros makes debugging much harder - you no longer have a stack trace (although GDB is fairly smart about this, it's still less than ideal).
I've started moving to using python to generate what I need a lot of the time now in C. I'll either make a '.h' file, read it in and generate the boilerplate I need, or just do it using native python and emitting the C I need.
I'm never again hand-writing an my_enum_to_str routine.
To add - the preprocessor is a pretty dated thing that merely uses text substitution, so you have no easy way to debug the code that the preprocessor passes to the compiler. Defines such as function-like macros throw away type safety and can have extremely unexpected behavior. For example, you might think this code will do what you want.
#define SQ(x) x*x
cout << SQ(2) // prints 4 since 2*2 = 4
cout << SQ(1+3) // prints 7 since 1+3*1+3 = 7
Macros are pretty much entirely unnecessary and should be avoided. Compilers inline nowadays, so you don’t really gain anything from using a macro when you could have just made a function that gives you type safety and intuitive behavior. If you are trying to define constants, use const, enum, or enum classes. If you are trying to define multiple versions of the same function, use polymorphism or templates. If you are trying to wrap around arbitrary code, use lambdas.
I agree that you shouldn't be doing this stuff in production if you don't know the ends and outs of doing this idiomatically. For instance, the lack of parenthesis ala
#define SQ(x) ((x)*(x))
set off my C spidey senses. I use them even for constants in pound defines just to be consistent.
That being said, there are benefits, like the type safety listed being one of them. No weird cast to void* and go to town on raw memory shenanigans you would have to do to use functions in intrusive collections in C.
Say no to masqueraded pointers! They require a specific coding convention that can't be checked by compilers since it is effectively a linear (or affine if you are pedantic) type. Put in the other way, masqueraded pointers make many otherwise non-destructive operations destructive without you realizing.
When you increment a pointer, it moves ahead by the sizeof the underlying concrete type. If the pointer is to void, there is no underlying type and in fact void pointer arithmetic is disallowed by the standard. GCC lets you do it with an extention: https://gcc.gnu.org/onlinedocs/gcc-4.8.0/gcc/Pointer-Arith.h...
So in this case, since the headers for the arrays are made up of two int's it's the right thing to do to move around by sizeof(int) memory address units. You do this with a cast before the arithmetic.
creates a type "STR" and the functions str_init, str_resize, str_getsize, str_append, str_shrink, str_truncate, str_get, str_iter, str_free, str_export, and str_exportdup.
>The rise of a new generation of low-level programming languages like Rust, Go and Zig has caused C and its primitive type system to fall into some disrepute.
One of these things is not like the others. I never understood why Go, being a garbage collected language, is grouped with systems programming languages like C or Rust. If anything its direct competitors performance/productivity-wise are probably C# or Java.
C is/was used for tons of Unix userspace programs that have no issue being written in something like Go. IMO this "systems" term has become a red herring and should be retired in favour of just naming concrete domains in a given discussion.
The vast majority of programs written in those languages are still relatively simple A->B things like grep or ls was when C was new. Go is a much simpler language than C# and Java - the GC isn't really the point.
Everyone likes to think, I can't use a GC for my work - I don't like garbage collection much either, but this is basically religion: it's just a tool, and it's a tool that makes programming easy.
Well, systems programming and apps programming are the domains in question, SP is about implementing the platform and infrastructure. There is no single defining characteristic since languages are used cross purposes, it's a term meant to characterise existing engineering practice. But if you really wanted an example of the least likely SP language, I'd say MATLAB or Prolog could be nominated.
Lisp and Java have been used in SP roles even though people often think of them as apps languages.
Probably most useful is to observe what usage languages see. Eg Go is used for many databases, K8s, gVisor, Docker etc.
> What is the defining characteristic of a 'systems language'
The precise technical definition is "whatever the speaker means by it". In other words, it's not a useful term.
People will come up with definitions like "whatever you can write an OS kernel/a compiler/a database management system in". So languages like Haskell, OCaml, and Java are certainly included. I don't see why Go shouldn't be.
Off topic: the top of the page call to action to sign up for updates would normally be a distraction but the checkboxes that define your intended audiences make me feel like you know how important it is to keep your content targeted without being annoying. Thanks, that's cool, also you offer an alternative via RSS right in the call to action, so I'm not suspicious that you want my email for any other reason, not that I normally would, but it's become an instinct at this point :)
C is still, I have to imagine, the closest thing we have to a language available for all platforms that exist today, while C++ is heavily burdened with featuritis and Rust is limited in platform support.
Rust supports everything you are likely to see in the wild outside of highly, highly specialized applications (e.g. ancient mainframes, satellites from the 80s or 90s, etc.).
For God's sake, it's becoming increasingly difficult to justify writing code that takes into account CPU endianness, because all CPUs that are likely to run your code are little endian!
99% of ARM usage is done in little endian. all android & ios phones, all embedded boards that ship with linux, etc. are always configured in little endian.
Okay, assuming you're right, how much overhead is it to consider endianness? I've never had issues with it, unless I'm implementing something fully from scratch, and that's rare in a production environment.
People that deign network protocols love love big endian.
Which means on the software side you then have to swap everything from big endian to little endian. And you need to do that at the first opportunity so their big endian crap doesn't get loose in the rest of the code.
Sometimes there isn't C++ or Rust. Many embedded platforms only have a C compiler. And sometimes an existing codebase is written in C, and adding some C++ or Rust creates undesired new dependencies. See the Linux kernel debate on using those languages.
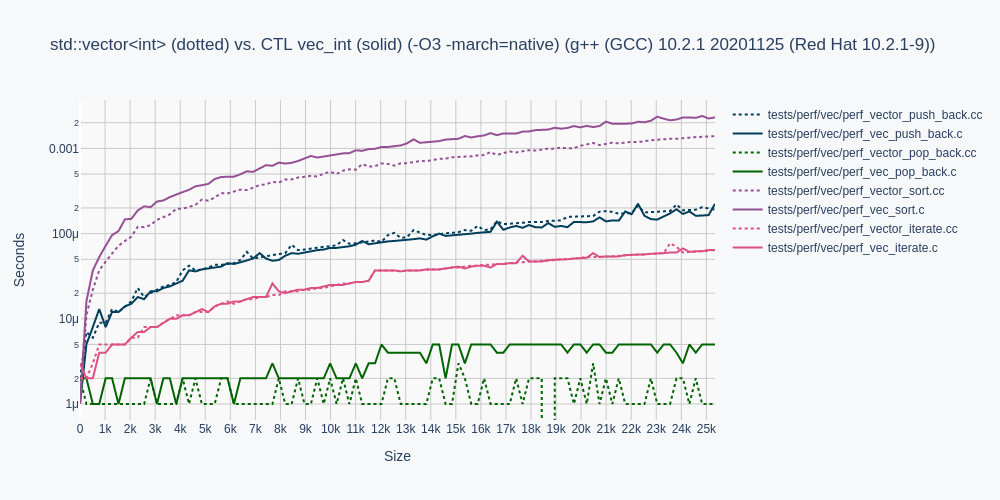
I favor the CTL over the STL anytime, because it compiles much faster, is much smaller, no indirect vtable calls, no bloated god objects, has no magic hooks attached, like dereferencing refs and ops, is clear on stack vs heap allocation.
The downside of course is that generics and iterators on those are a bit more troublesome, only compiler dependent goodies (mostly only clang, not gcc), like overloads or constexpr. C++ templates are ugly, and the STL is very buggy and limited. Also no security and no performance. They started on the wrong foot and had to keep it there.
Rust has an annoying syntax, but a much better library culture.
I haven't written the STL critic parts yet. The testsuite contains a lot of hints.
Major quirks: no proper allocation/resize upfront, when you know how big the resulting vector will be. Also not much help with bulk inserts. (Like a proper set join). The 3 STL's I tested massively overallocate.
Unordered containers allow ranges, iterators from some to some, whilst they are unordered by default. This begs for bugs.
Ranges are pairs? How broken is that? Iters need to be fat and ranges. Starting with a broken design upfront does not help.
Set and hashmaps have to use the slowest datastructures, because they considered better ones as too experimental. Hence no open hashmaps, just chained and rb trees. Their arguments of pointer and iterator stability is just an excuse after this decision. Everybody can work around that, and use open hashmaps and btree's just fine.
How about 3way comparison safety in set? It is not. They just found out recently.
No hashtable security, none. Slow, too big and insecure, how nice is that. 0 out if 3.
No sorted vectors, no small (stack) vectors.
No strings. Better than POSIX C, fine. But still no unicode support and identifier (names) support. How would you search for an international string? With accents and different normalization? You wont find it. Strings are not binary buffers.
Formally verified? Not, just 2 parts out of 20. This would have found the 3way compare problems, or their forward_list problems.
forward_list, one of the most basic datastructures, heavily used since the 50ies in Lisp. So why does lisp still has much better support for it than the STL? Cycle detection, length, shuffle, ...?
The manual free is of course annoying, agreed. Ditto the missing operator overloading, which is even worse. Or default args.
the gigabytes of STL-using C++ code that works just fine shows that most of them aren't serious issues. In ~15 years of C++ I have never had any issues with ranges being pairs, strings (though in my opinion string handling shouldn't be part of programming languages at all - they should just be treated as opaque binary blobs like you would pass to eg zlib or libpng), forward_list...
Also, all the interfaces of the STL being quite precise mean that
> Set and hashmaps have to use the slowest datastructures, because they considered better ones as too experimental. Hence no open hashmaps, just chained and rb trees. Their arguments of pointer and iterator stability is just an excuse after this decision. Everybody can work around that, and use open hashmaps and btree's just fine.
> No sorted vectors, no small (stack) vectors.
are non-issues: in my own software I can swap std::unordered_map, std::vector, etc... trivially for other containers only by changing their type and adding an include. e.g. in my codebase I have some boost::small_vector<>, boost::static_vector<>, pod_vector<>, flat_set, flat_map, and 4/5 different hash maps which are all chosen specifically for their performance characteristics on various use cases.
In particular if it was C instead, I would have had to change every single call to add, remove, iterate, etc. every time.
{kind=link}