This is the sparsest model thats been put out in a while (maybe ever, kinda forget the shapes of googles old sparse models). This probably wont be a great tradeoff for chat servers, but could be good for local stuff if you have 512GB of ram with your cpu.
It has 480B parameters total, apparently. You would only need 512GB of RAM if you were running at 8-bit. It could probably fit into 256GB at 4-bit, and 4-bit quantization is broadly accepted as a good trade-off these days. Still... that's a lot of memory.
I know quantizing larger models seems to be more forgiving but I’m wondering if that applies less to these extreme-MoE models. It seems to be that it should be more like quantizing a 3B model.
4-bit is fine for models of all sizes, in my experience.
The only reason I personally don’t quantize tiny models very much is because I don’t have to, not because the accuracy gains from running at 8-bit or fp16 are that great. I tried out 4-bit Phi-3 yesterday, and it was just fine.
The old google's Switch-C transformer [1] had 2048 experts, 1.6T parameters, with only one activated for each layer, so much more sparse. But also severely undertrained as the other models of that era, and thus useless now.
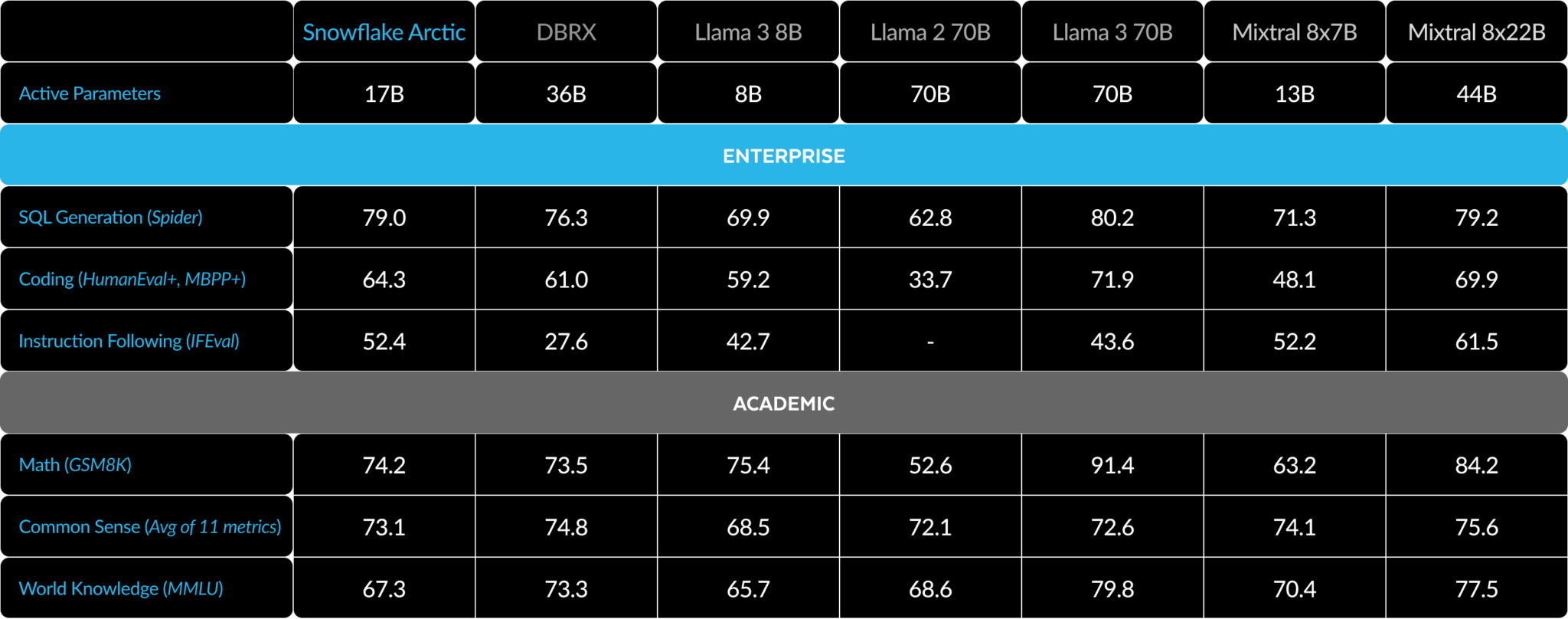
Where do you see that? This comparison[0] shows it outperforming Llama-3-8B on 5 out of 6 benchmarks. I'm not going to claim that this model looks incredible, but it's not that easily dismissed for a model that has the compute complexity of a 17B model.
{kind=link}